PHP 接口使用 Gzip 响应大体积的数据与 Javascript 客户端解码方法
最终实现
当传输较大的数据内容时,客户端往往传输会非常慢且超时,Postman也会直接 Error: Maximum response size reached 拒绝服务。为此我们需要将数据压缩起来,然后再返回给前端。
前端也可以得到数据后自行解密。一般来说接口大多返回的都是数据库的数据表,这类数据往往都是成对出现,且有很大内容的重复性,比如字段名重复、高频次的0、1、ID 等,那么压缩率就非常可观。
PHP代码端:
<?php
$list = Db::table('users')->get()->toArray();
$result = json_encode(['error' => 0, 'data' => $list]); // 假设 $result 是最终返回给客户端的 json 数据
// 将数据通过 GZIP 压缩
$binaryData = gzencode($result);
// # 如果是单文件
header('Content-Encoding: gzip');
echo $binaryData;
// # 如果是 laravel 在控制器中。
public function getUsers(){
// ...
$binaryData = gzencode($result);
return response(($binaryData))->withHeaders([
'Content-disposition' => 'attachment;',
'Access-Control-Expose-Headers' => 'Content-Disposition',
'Content-Type' => 'application/octet-stream',
'Content-Encoding' => 'gzip',
]);
}
前端JS:
axios.get('http://127.0.0.1:9999/a.php',{}).then(res=>{
console.log('res.data:',res.data)// 解压过的数据
})
到这里基本就够用了,由于 GZIP 的通用性,浏览器基本都已经支持了 GZIP 的数据解压,只需要在 Response Header 字段中增加一个 Content-Encoding: gzip,浏览器就会自动帮你做这件事。如果有 Nginx 或者前置CDN,也可以在 Nginx 端配置GZIP压缩会更方便。
详细想了解,关于哪些浏览器支持 GZIP 可以查看 https://caniuse.com/?search=gzip
手动解压数据
那么也可以想想,如果你只是想传输压缩过的二进制数据,要如何才能够自己解压呢?
PHP 端依然只输出二进制数据,而不增加标志头 Content-Encoding
<?php
$list = Db::table('users')->get()->toArray();
$result = json_encode(['error' => 0, 'data' => $list]); // 假设 $result 是最终返回给客户端的 json 数据
// 将数据通过 GZIP 压缩
$binaryData = gzencode($result);
echo $binaryData;而 Javascript端,此时也只需要增加一个参数,拿到完整的二进制数据,然后进行解压。
这里需要在 node 环境下运行。
var zlib = require('zlib');
axios.get('http://127.0.0.1:9999/a.php',{responseType: 'arraybuffer'}).then(res=>{
console.log('res.data:',res.data) // ArrayBuffer
console.log('res.data2:',Buffer.from(res.data)) // Uint8Array
console.log('depress', zlib.unzipSync( Buffer.from(res.data)).toString()) // 解压后数据
})想想更多
如果说不传递 responseType 呢?那取到的是文本数据,将无法完整还原至二进制,进而进行解压数据。
如这样:
var zlib = require('zlib');
axios.get('http://127.0.0.1:9999/a.php').then(res=>{
console.log('res.data:',res.data) // string,字节数变大
console.log('res.data2:',Buffer.from(res.data)) // Uint8Array,数据不对,有一些相似
console.log('depress', zlib.unzipSync( Buffer.from(res.data)).toString()) // 解压失败
})见图中,左侧是错误读取的,右侧是正确读取的。 数据长度多出一些,且数据有一定的相似程度。

这里取到的直接数据是 string,由于数据是 string,会将二进制很多不可见的字符丢失,再次转为 ArrayBuffer 时,数据是不对的。存在一些丢失,和一些读取编码标准的问题,导致一个字符当 2个、3个去读,整体的字节会增多。
你想知道如何正确读取 string 并转为 ArrayBuffer 或者Uint8Array?应该没有或者很难。
浏览器端并没有原始的二进制处理方法,你从axios拿到数据时,可以认为是从一个管道里提取二进制数据,而浏览器并没有二进制数据,你需要将他转换为可见的逻辑类型,如 string、ArrayBuffer等, 其中 ArrayBuffer 就是一种二进制表示方式,只是它存储成了类似数组的对象。一旦你从管道里把数据按照 string 的标准,如 UTF8 编码读取且存储起来了,那就会丢失一些 UTF8 编码以外的数据,那么再次转换为逻辑意义的 ArrayBuffer 时,就会丢失数据。
最好就是保留 ArrayBuffer 数据,你可以随时进行转换为别的数据格式。
在上面的业务中,也可以通过后端将压缩过的数据,再次进行 Base64 编码,Base64 是可见的。你可以将这种字符串传输到前端,再通过 Base64 编码还原为具体的 ArrayBuffer,之后进行解码等操作。
如这样:
<?php
//...
$res = file_get_contents('test2.txt');
echo base64_encode($res);前端不需要指定 responseType:
axios.get('http://127.0.0.1:9999/a.php',{}).then(res=>{
console.log('resposne length:'+ res.data.length)
const binary = Buffer.from(res.data,'base64')
console.log('binary:', binary)
console.log('decompress', zlib.unzipSync( binary ).toString())
})执行结果如下:
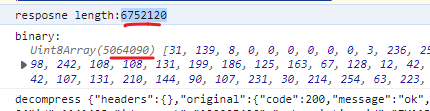
看到传输的数据比实际的数据明显有增大,因为 Base64 表示的字符有限,因为它只有64个字符重复使用,来表示未知的二进制数据,你也可以将其扩展为 "Base128" 等,自己实现一套编码规则。
关于 ArrayBuffer 和Uint8Array的相关讲解,可以参考至:ArrayBuffer,二进制数组
总之还是在尽可能支持 ArrayBuffer 或 Uint8Array 的时候,使用它才能够保证数据完整性。字符串因为编码问题很容易丢失数据,实在想要用,BASE64 也是一种做法。
Postman Error: Maximum response size reached
当你修改完 gzip 传输之后依然会报这个错误,并不是因为 gzip 压缩的不够小,而是 Postman 判断的是 gzip 解压后的数据大小。
只需要在设置里判断修改下就行,改为符合你业务需求的大小。